AIを使うアプリをAIに作らせる
バイブコーディングでAndroid向けのオフラインAI翻訳アプリを作る話。
AIコーディングエージェントの進化がすごく、今ではもう手放せないような存在になっているように感じる。 一昔前までは「なんだか自分で実装した方が速くて正確だなぁ」みたいなことを思っていたが、最近のフロンティアモデルは初手で7割ぐらい正確なコードを爆速で生成してくれる。そこから気になった箇所の指摘を数往復程度すれば十分な品質のコードが完成するので、もはや手で実装するよりも全然効率が良い。
もっとも、業務で実装するコードに関してはその残り3割の部分をきちんとつぶす意味でも、AIが生成したコードをそれなりにちゃんとレビューする必要がある。 人間よりもAIの方がコードを生成する速度がずっと速いので、結果として人間がレビューする頻度や負荷が増えているし、人間のレビュー速度が開発速度の律速になっているように感じる。
一方で、自分用に趣味で開発するアプリに関しては多少コードの品質が悪かったところで影響を受けるのは自分ぐらいなので、セキュリティ上の懸念がないようなものであれば自己責任でAIに生成させたコードをろくにレビューもせずにそのまま動かすことができる。
今回は、そうした業務ではできないようなバイブコーディングスタイルで自分用のAndroidアプリを作ってみた。
オフラインAI翻訳アプリを作る
業務都合でなんやかんやあって、短期ではあるが出張でアメリカに行くことが決まった。 英語の技術文章を読むぐらいならともかく、英会話ができる気が全くしないのでちょうど良いと思い、翻訳アプリを作ってみることにした。
翻訳アプリなんてGoogle翻訳で良いじゃんと思うかもしれないが、今回はちょっとしたこだわりで完全オフラインでも動作する音声入力機能付きの翻訳アプリを作ることにした。 というのも、展示会やイベント会場のような人が多く混雑している場所だとネットワークが不安定でまともに通信できない場合があるという話を聞いたからである。
Google翻訳アプリにもオフラインモデルをダウンロードする機能があり、事前に使用する言語のモデルをダウンロードしておけばオフラインでもテキスト翻訳を行うことができる。 しかし、オフライン時は音声入力が利用できないため、対面での会話などを想定するとかなり不便である。
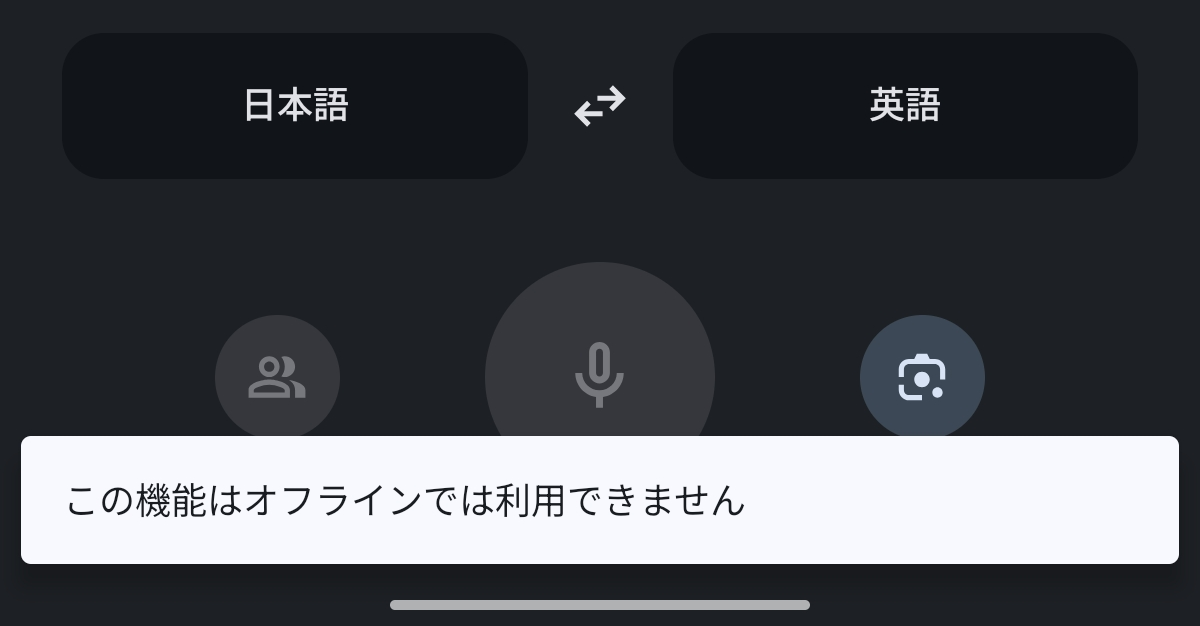
最終的に出来上がったもの
最終的に完成したアプリのデモがこちらである。
言語に対応するボタンを押すとプッシュトゥートークで音声入力が行われ、話し終わると認識したテキストと翻訳結果が表示される。
音声認識にはAndroidのSpeechRecognizer APIを使用しており、翻訳にはGemma 3nのE4Bモデルを使用している。 機内モードのアイコンが出ていることからも分かるように、翻訳処理は端末上で完結しているため完全オフラインで動作する。 動画は等倍再生で、実際に端末上でこの速度で動作する。
また、翻訳結果のテキストをAndroidのTextToSpeech APIを使って音声出力する機能も実装した。
Gemma 3nは音声入力も可能なため、SpeechRecognizerを介さずに直接Gemma 3nに音声を入力して翻訳させるモードも実装している。 基本的にSpeechRecognizerで十分だが、Gemma 3nの方が認識速度と引き換えに若干ノイズ交じりの音声でも認識してくれるような気がする。
ソースコードとビルド済みAPKはこちらのリポジトリで公開しているので、興味のある人は試してみてほしい。
アーキテクチャの検討
オフラインで動作させるためには音声認識や翻訳処理を端末上で完結させる必要がある。 以前からWhisperやGemmaがスマホ上でも十分動くというような話を聞いていたので、まぁ何とかなるだろうと思って「WhisperとGemmaで翻訳するアプリを良い感じによろしく」と雑なプロンプトをAIに投げて実装させた。
試行錯誤の結果
そこからAIが実装したものをいろいろと試してみた結果、STTに関してはWhisperを使わなくてもAndroidのSpeechRecognizer APIを使えばオフラインでも高速に十分精度良く文字起こしができることが分かった。
SpeechRecognizerは端末の音声認識サービス(多くはGoogle音声入力)を利用しており、通常はオンラインで動作するが事前にオフライン用の音声入力モデルをダウンロードしておけばオフラインでも問題なく動作する。

翻訳に関してはGemma 3nのE4Bモデルが品質も良くLiteRT-LMランタイム上で十分実用的な速度で動作することが分かったのでコレを採用することにした。 LiteRT-LMランタイムを使用した推論処理をAIに実装させる際にはGoogle AI Edge Galleryアプリのリポジトリをリファレンスとして渡すのが非常に効果的だった。[1]
上手くいかなかったもの
llama.cppによるCPU推論
初期実装ではLLM・SLMを動かすのにllama.cppを組み込んだネイティブランタイムを使用していた。 llama.cppはCPU推論なので動作するはするものの、会話に使用するにはややレイテンシが高くてあまり実用的ではなかった。
Gemma 3の1B/4Bモデル
続いてMediaPipeやQualcomm NPUバックエンドでGemma 3の1Bモデルを動かしてみた。これは非常に高速に動作したものの、翻訳品質がとても実用的なレベルではなかった。 単語単体で翻訳させればそれなりに正しい結果が出るものの、少し複雑な文章を入力すると翻訳を放棄して原文をそのまま出力したり、翻訳結果がループして無限に生成され続けてしまったりしてしまうことが多かった。
それではモデルサイズを大きくすれば良いのかと思ったが、Google AI EdgeのページではGemma 3の1Bモデルしか提供されていない。
そこで、Gemma 3の4Bモデルを動かすべくドキュメントに記載されている方法[2][3]でモデルの変換を試みた。 litert-torchには4Bモデルを変換する実装が無かったものの、4Bモデルの変換をサポートするPRが出ていたのでこのPRをもとに手元で4Bモデルの変換を行ってみた。
WSLのメモリを60GBほど消費したものの変換自体は上手くいき、端末上で推論実行まで行うことができた。 しかし、トークン周りの処理が正しくないようで意味のない出力が生成される状態になってしまった。
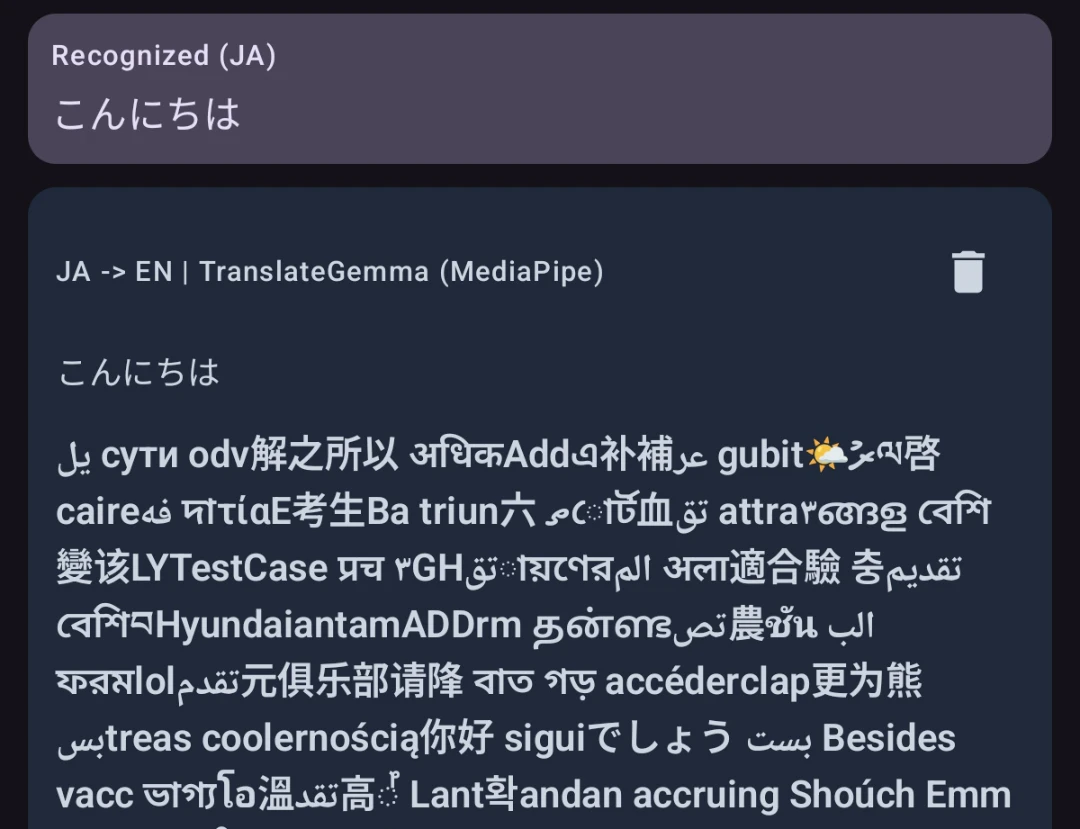
この問題についてはしばらく調べてみたものの解決できなかったため、Gemma 3の4Bモデルを動かすのは断念した。 TranslateGemmaの4Bモデルについても試してみたものの、同様の問題で上手く動作させられなかった。
将来的にTranslateGemmaの4BモデルなどがLiteRTで正式にサポートされれば、そちらを使用した方がより高精度な翻訳ができるようになると思われる。
スクロールバーの実装
AIが意外と苦戦していたのがスクロールバーの実装である。
今回はアプリ全体をGPT-5.3-Codexを使用して実装したが、スクロールバーに関しては正しく表示されなかったりバーの長さ計算がおかしかったりして満足のいく実装ができなかった。 繰り返し実装させてみたものの埒が明かないので、そこだけClaude Opus 4.6に頼んだらめちゃくちゃ長考したうえで一発で正しい実装をしてくれた。
おわりに
バイブコーディングでAndroid向けのオフラインAI翻訳アプリを作ってみたが、予想以上にすんなりと開発することができた。
生成されたコードは全然レビューしていないのでトンデモ実装が混ざっている可能性はあるが、少なくともアプリの動作としては自分用で使う分には十分な品質であるように思う。 自分はAndroidアプリ開発の経験がほとんどないので、この規模のアプリを一から実装する場合は調査なども含めて1か月ぐらいはかかりそうなものだが、今回は試行錯誤を含めてもわずか3日程度でできてしまった。
冒頭でも書いたように、今はまだ業務で実装するコードにAIを使う場合はきちんとAIが生成したコードをレビューしたうえで使っているが、そのうちコードよりもAIプロンプトをレビューしていくような開発スタイルにシフトしていくのかもしれない。
一昔前にアセンブリ言語→高水準言語のようにソフトウェア開発における抽象度が上がったように、今度は高水準言語→AIプロンプトのようにさらに抽象度が上がるような気がする。 そのうちAIプロンプトの解析ツールが出てきて、仕様的に矛盾していたり記載が不十分な箇所にはビルドエラーのように赤線が引かれるようになるのかもしれない。 計算資源が十分増えた未来では、ソフトウェアはAIプロンプトの中間表現のような形で出荷されて、端末上で実行する直前にJITでプロンプトからコード生成されるようになるのかもしれない。[4]
自分で一から設計して実装を起こして、一発で設計通りに全部導通したときの快感を味わうような開発を行えるのはもう今のうちだけかもしれないと思うと少し寂しい気分になるが、今後は高度で複雑なソフトウェアをより短い時間と工数で作れるようになると思うと世の中が大きく変わりそうで楽しみである。